Assignment 1 Classification Modelling with Automotive Data
Developing classification models to identify customers likely to repurchase from automotive data. Comparing GLMNET, random forest and xgboost predictions, selecting the best model and communicating outcomes to the audience


- Author
- Joshua McCarthy
- Published
- Sun, May 3 2020
- Last Updated
- Sun, May 3 2020
Context
Again the goal was delivering a report accessible to the target audience, drawing on 'how might we' and refining how I select and communicate outcomes with data and detail heavy requirements. I further explored feature engineering, creating a more complex wear metric, that recognised how both age distance traveled effected attributed to the "wear" on a vehicle.
You are now a Data Scientist working for an international consulting firm. An automotive manufacturer has approached you to help them target existing customers for a re-purchase campaign. The aim of this campaign is to send a communication to customers who are highly likely to purchase a new vehicle. All customers have already purchased at least one vehicle.
Remember to consider your audience!
Report
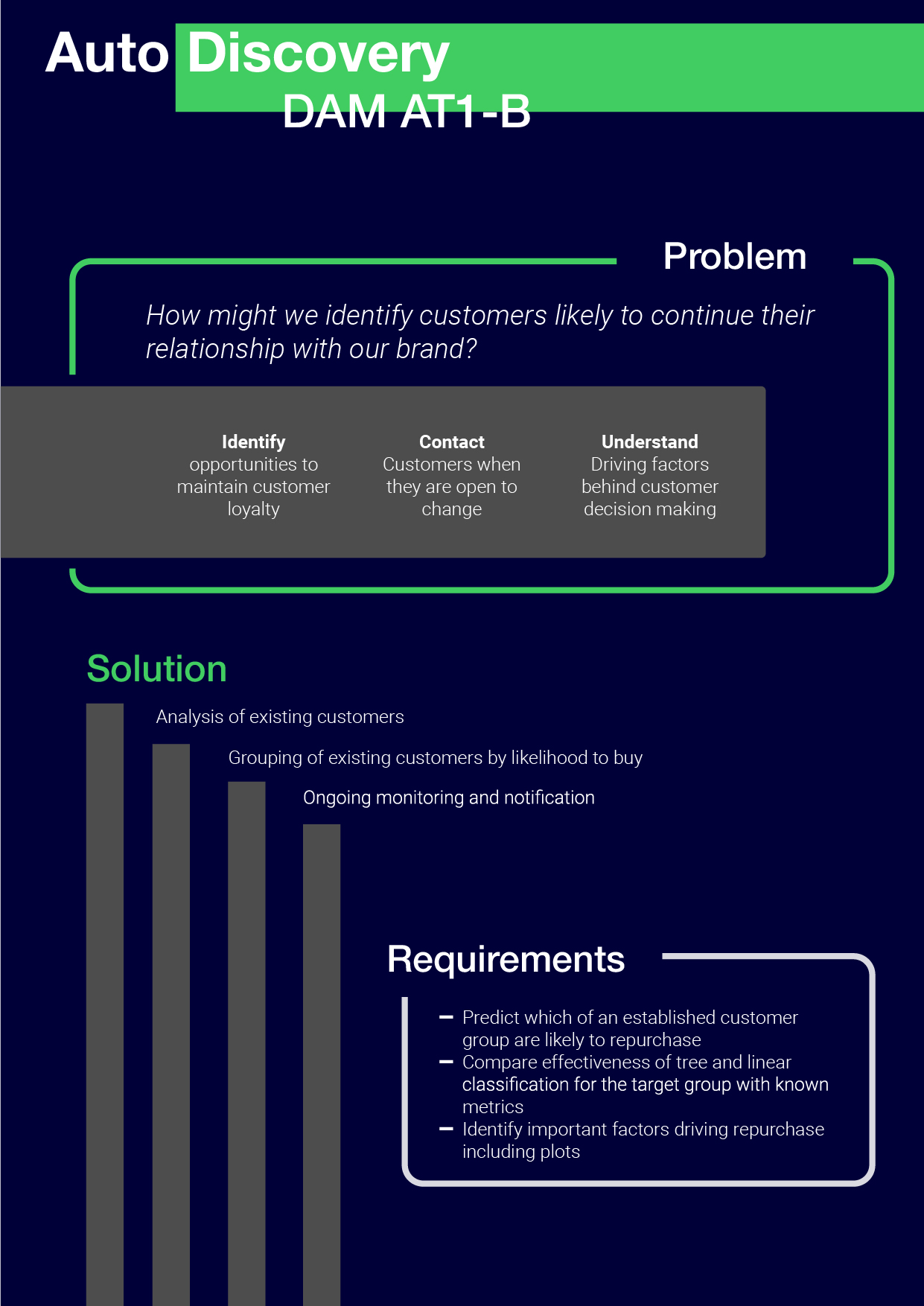
Report Page 1, challenges, solutions, requirements
Simpler graphing styles were utilised for ease of interpretation, where more complex solutions would require some explanation that may or may not be read.
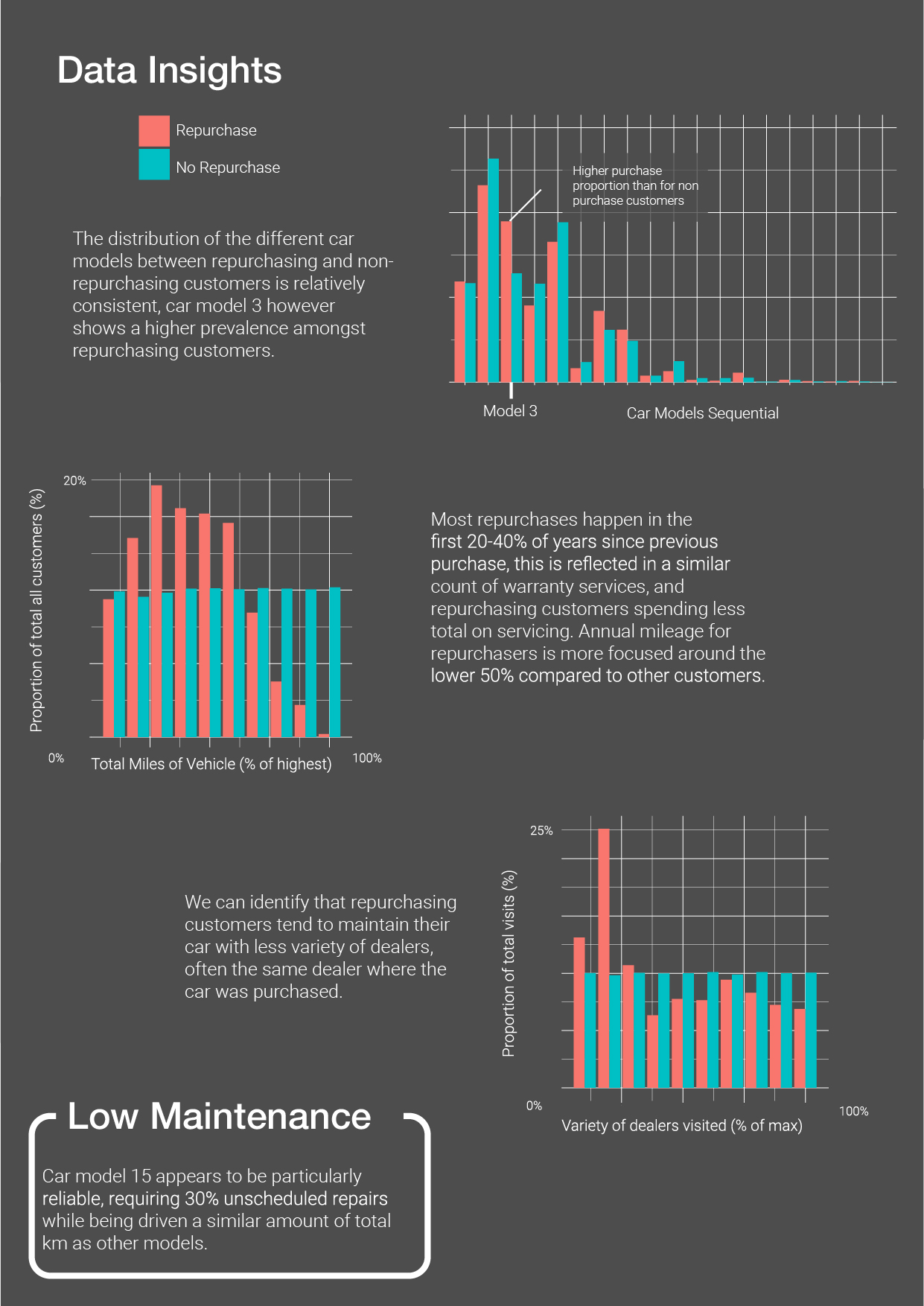
Report Page 2, data insights bar graphs, repurchasing habits including mileage and age, customer loyalty
My approach to feature engineering began with an exploration of the customer's relationship with their vehicle, investigating how this might be reflected in their interactions with the dealerships and recorded in the dataset, and finally evaluating the new features' effect on the model. The features engineered through this approach could therefore stand alone as ongoing evaluation metrics for the user, in addition to improving the model. Following exploration of these value add avenues, feature engineering through data interrogation and transformation further developed the model. In real challenges, during this second phase I would look to rationalise any engineered features against possible causes, as I feel there is a risk in creating features that overfit the model to the data, as they may exploit a deficiency in the data rather than a real world cause that is generalisable.
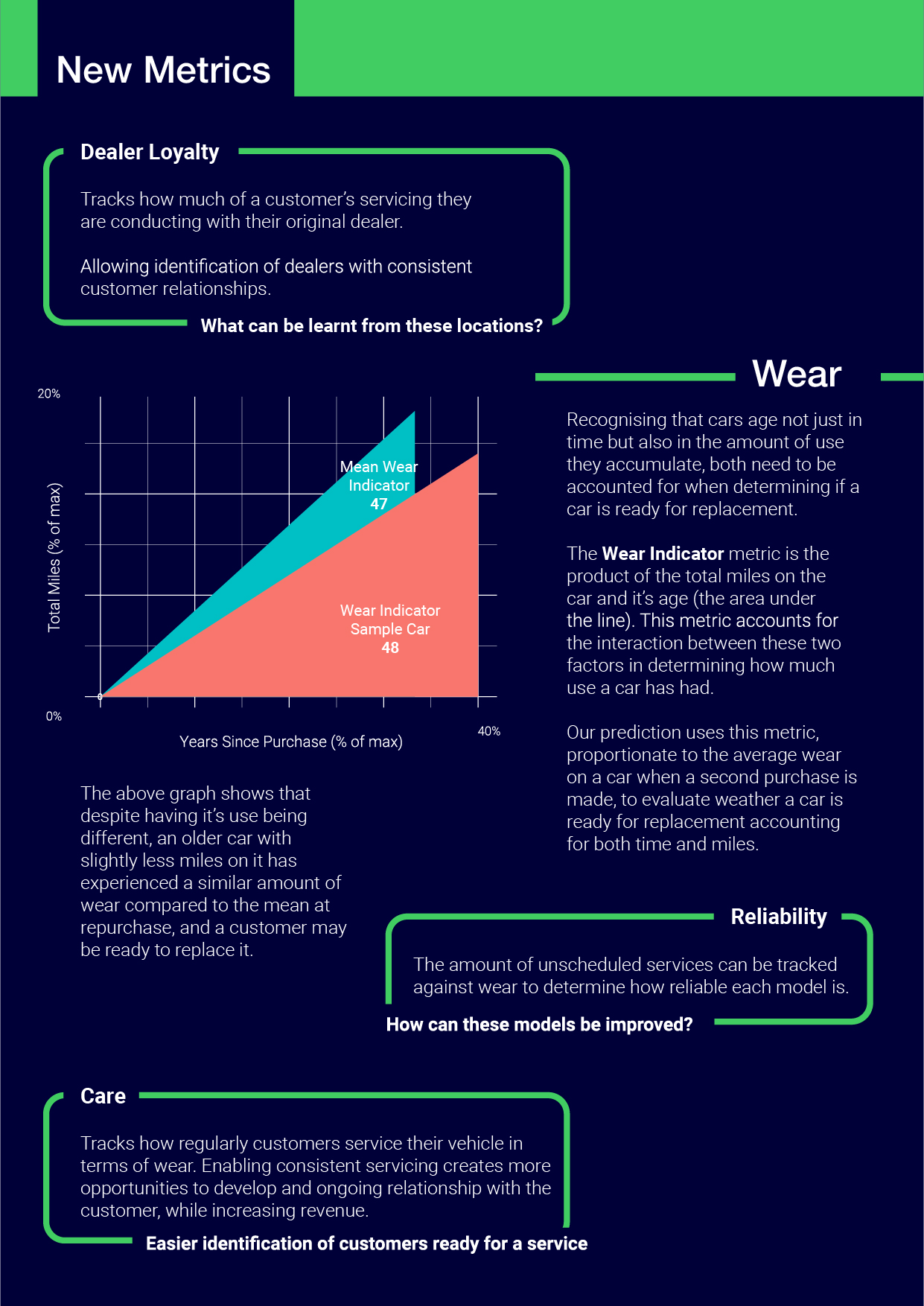
Report Page 3, new metrics, dealer loyalty, wear, model reliability and vehicle care
Structuring a comparison and evaluation of different modelling methods which clearly communicated with the target audience in a way that would reduce their engagement proved a challenging deliverable. The inclusion of customer privacy information on this page was a poor choice, as this is important information and this page is the most likely to be skipped.

Report Page 4, model comparison, comparison metrics, precision, recall, AUC, F1 score, variable importance, customer privacy
During analysis I identified customers leaving the brand as a potential avenue for exploration that further addressed the clients needs though not an assessment deliverable, this was included as a next step.
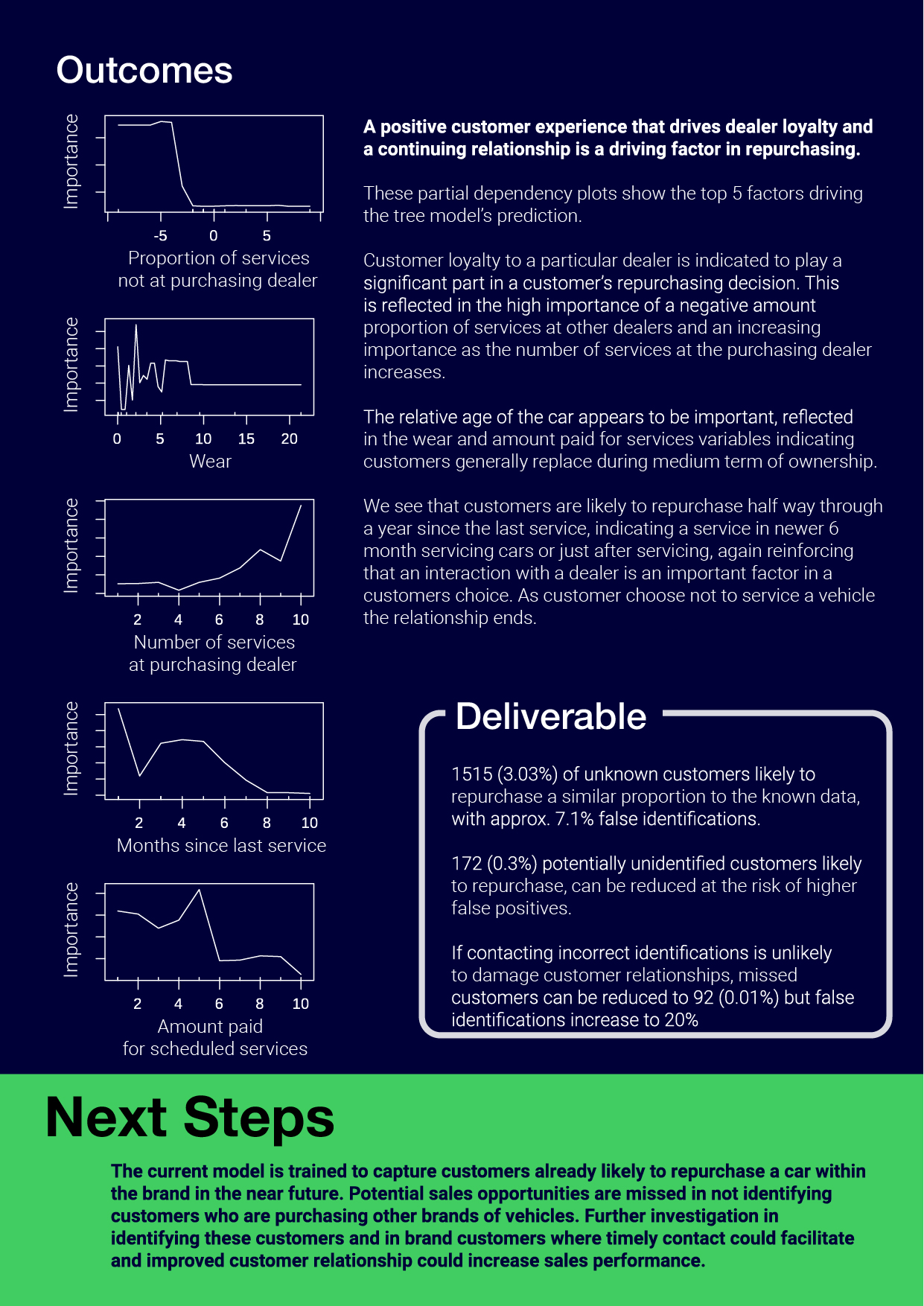
Report Page 5, variable importance, outcomes, deliverables including model accuracy, next steps